이번 Yolo는 논문 형식이 참 독특했습니다. 각 논문의 구성을 따르되 소제목이 일반적이지 않아 신기하게 다가왔습니다.
이번 논문은 짧게 리뷰를 진행해 보겠습니다.
기존 yolov2 모델과의 차이점과 큰 메소드들에 대해서 설명하겠습니다.
성능을 향상시킨 첫번째 기법은 loss의 도메인 변경입니다. yolov2 까지만 해도 feature map 공간에서 물체의 위치를 예측하고 디코딩 과정을 통해 이미지 전체에서 box을 찾았습니다. v3에서는 그렇게 진행하지 않습니다. 입력 이미지에서 box를 직접 회귀 합니다. 값이 커진만큼 L2 loss를 사용한다면 값이 폭주하는 경우가 발생할 수 있으니 L1 loss를 사용합니다.

IoU를 기준으로 가장 높은 값을 1로 지정하고, IoU 임계값은 0.5로 사용합니다. Box가 ground truth에 할당 되지 않는다면, 좌표 및 클래스 예측에는 영향 없이, objectness에만 loss를 적용합니다. 즉, ground truth와 0.5 이상의 IoU를 갖는 box에 대해서만 prediction, localization을 진행한다는 의미입니다.
모든 box에 대해서 multi-label classification softmax를 사용했을 때 성능면에서 우수하지 못했다고 합니다. 그래서 Class당 binary cross-entropy를 사용해서 우수한 결과를 얻었습니다. 이러한 방식은 복잡한(label이 많이 겹치는 상황 등) domain에서 classification하는데 도움이 됩니다.
yolov2에서 5개의 anchor box를 사용했지만 이번에는 3개만 사용하며 동일하게 clustering을 통해서 획득합니다.
Darknet-19보다 더 깊은 Darknet-53을 제안합니다. 기존의 19모델은 VGG를 활용했다면 53의 경우네는 Residual network를 활용하였습니다. ResNet보다 더 좋은 효율성을 보입니다.

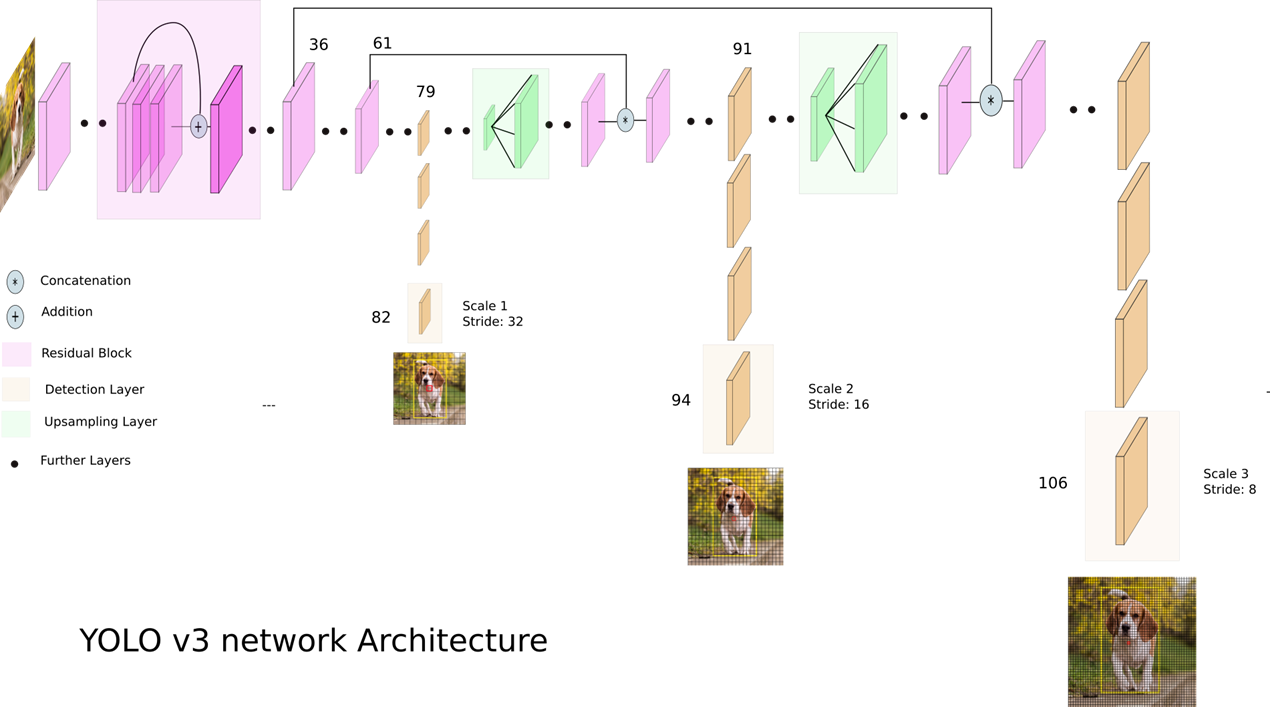
전체 v3의 구조는 다음과 같습니다. FPN 처럼 feature fusion도 진행하고, 각 feature 대해서 추론을 합니다. fusion 과정 중에는 concationation을 통해 정보 합칩니다.
성능면에서 RetinaNet에게 밀렸으나 속도 면에서 훨씬 빠르다는 것을 그래프를 통해서 놀리고(?) 있습니다. RetinaNet 논문의 그래프를 그대로 가져오면서 자신들의 모델만 끼워 놓아 놨습니다. 그 이외에도 focal loss를 적용했는데 성능이 오히려 낮아졌다는 등의 표현을 했습니다.

더 놀라운 점은 이번 논문에서 COCO 데이터셋에대한 metric이 이상하다면 비판하였고, 자신의 기술이 전쟁과 에서 사람을 죽이거나, 끔찍한 짓을 하는데 이용되었다고 말하고 윤리적 책임을 느낀다고 말했습니다. 그리고 나서 이 이후로 yolo 시리즈는 다른 저자가 연구를 진행하게됩니다.



