Detection을 분야에서 R-CNN의 최종 버전이라고 볼 수 있는 Faster R-CNN을 읽었고 리뷰해보겠습니다. R-CNN이 제안된 이후로 R-CNN이 가지는 단점들을 보안하기 위해서 Fast R-CNN이 등장했습니다. R-CNN이 가졌던 모든 region proposals에 대한 무수한 연산이 가져오던 과도환 시간비용을 줄이기 위함이었습니다. Fast R-CNN은 그것을 RoI pooling과 multi task loss로 해결하려고 했습니다. 하지만 실시간 속도의 감지를 달성할 수는 없었습니다. 그래서 제안된 이 점을 보안하기 위해 제안된 모델이 바로 Faster R-CNN입니다.
Abstract
물체의 위치를 예측하기 위해서는 region proposals 작업이 꼭 필요하다고 말하고 있습니다. 하지만 모델들이 입력에 대해서 추론을 진행할 수 있는 상태임에도 불구하고 selective search의 지연 때문에 입력이 들어오지 못해서 생기는 병목현상이 발생되어왔습니다.
따라서, Faster R-CNN는 이 부분을 집중 공략합니다. 직렬적이어서 병목현상이 발생했다는 점을 파악하고 RPN (Region Proposal Netwrok) 도입합니다.
PASCAL VOC 기준 78.8 mAP 성능을 보이며 속도면에서도 우수함을 드러냈습니다.
Architecture
바로 Faster R-CNN의 구조에 대해서 설명해보겠습니다. 왜냐하면 이 논문의 핵심은 selective search를 RPN으로 바꾸면서 얻었던 효과이기 때문입니다.

왜 RPN이 썼을 때 빨리 지는지를 알아보겠습니다.
RPN(Region Proposal Network)
원본 이미지를 통해 Fast R-CNN때와 같이 feature map(w*h size)을 우선적으로 획득합니다. 그러고 나서는 size를 유지하는 3x3 convolution을 진행합니다. 그 후에 병렬적으로 2회의 1x1 convolution을 진행합니다. Feature map의 가로 세로 사이즈는 유지하면서 채널 size만 늘리는 convolution 연산입니다. 왜 2회냐면 classification을 위한 정보를 담고 있는 feature map과 bouding box regression을 위한 정보를 담고 있는 feature map을 따로 구분 짓기 위함입니다.

그러면 RPN을 거치면 나면 나오는 feature map은 2개이고, 각 feature map의 shape는 아래와 같습니다.
- For classification : w * h * 9 * 2
- For bounding box regression : w * h * 9 * 2
이 숫자들을 해석할 필요가 있습니다. 2, 4, 9는 무엇을 의미하는지 알아보겠습니다.
9는 각 grid cell에 대한 anchor box를 의미합니다. 먼저 grid cell은 feature map에서의 pixel이라고 생각하면 이해하기가 편합니다. w * h 크기의 feature map이었으므로 feature map은 w*h개의 grid cell을 가지고 있습니다.
그러면 anchor box는 무엇일까요? Anchor box는 bounding box를 예측을 돕는 도구입니다.
각 cell 마다 적당한 크기의 anchor box를 미리 생성해 놓고 학습 파라미터를 통해서 물체의 크기에 맞게 anchor box를 조정해 주는 겁니다. 따라서 Faster R-CNN은 각 cell 마다 9개의 anchor box를 활용하여 region을 정보를 얻습니다.

그러면 w * h * 9라는 것은 feature map에서의 각 cell에 대한 anchor box가 가지고 있는 정보를 말하고 있습니다.
나머지 2와 4는 각 목적을 위한 학습 파라미터 일 수밖에 없습니다.
Classification을 위한 2는 물체가 있는지 없는지 여부를 나타냅니다. ( 물체가 있을 확률, 물체가 없을 확률 )로 objectness score를 표현합니다.
Bounding box regrssion을 위한 4는 anchor box를 크기 및 위치를 조정하는 값들을 담고 있습니다. ( 좌측 상단 x의 이동량, 좌측 상단 y의 이동량, w의 변화량, h의 변화량) 이렇게 파라미터를 가지고 있습니다.

RPN을 학습하는 방법에 대해 설명하겠습니다. 먼저 Positive example과 Negative example로 나누어 줍니다. Feature map 위의 모든 anchor와 ground truth와의 IoU를 비교하여 positive와 negative를 구분합니다. 0.3 이하는 negative 처리하고 IoU가 높은 거부터 positive 영역에 포함시켜 1 :1의 비율을 맞춰줍니다.
그러고 나서는 아래 Multi task loss 함수를 정의해서 학습시켜줍니다.

위 과정을 통해서 RPN을 이해했습니다. RPN의 장점을 정리해 볼 수 있습니다. RPN은 학습 파라미터를 통해 좀 더 정교한 region proposal을 획득할 수 있다는 장점과 딥러닝 파이프라인을 통해서 region을 획득할 수 있다는 것은 GPU를 사용하기에 용이하다는 점입니다. GPU를 사용해서 region을 얻을 수 있으므로 빨라질 수 있었습니다.
Training
Faster R-CNN을 구현해보면서 느꼈던 가장 큰 단점을 바로 학습 과정입니다. 학습 과정이 너무나 복잡했습니다.
총 4단계에 걸쳐 번갈아 훈련시키는 Alternating training기법을 사용했다고 합니다.
과정은 아래와 같습니다.

Feature extract layer, RPN을 고정, 고정 해제해 가면서 학습을 진행합니다. 논문 발표 후에는 위 방법보다는 Joint training 기법이 더 좋을 효율을 보였다고 합니다.
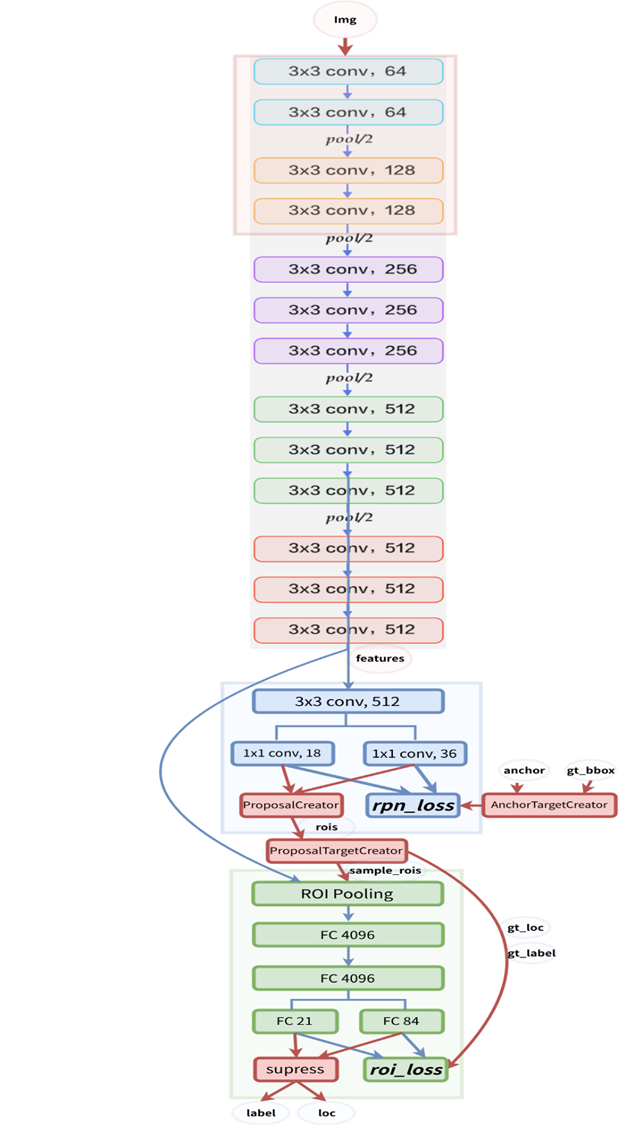
Faster R-CNN의 설계도입니다. 코딩 연습을 해보실 때 도움이 될 겁니다.
Results
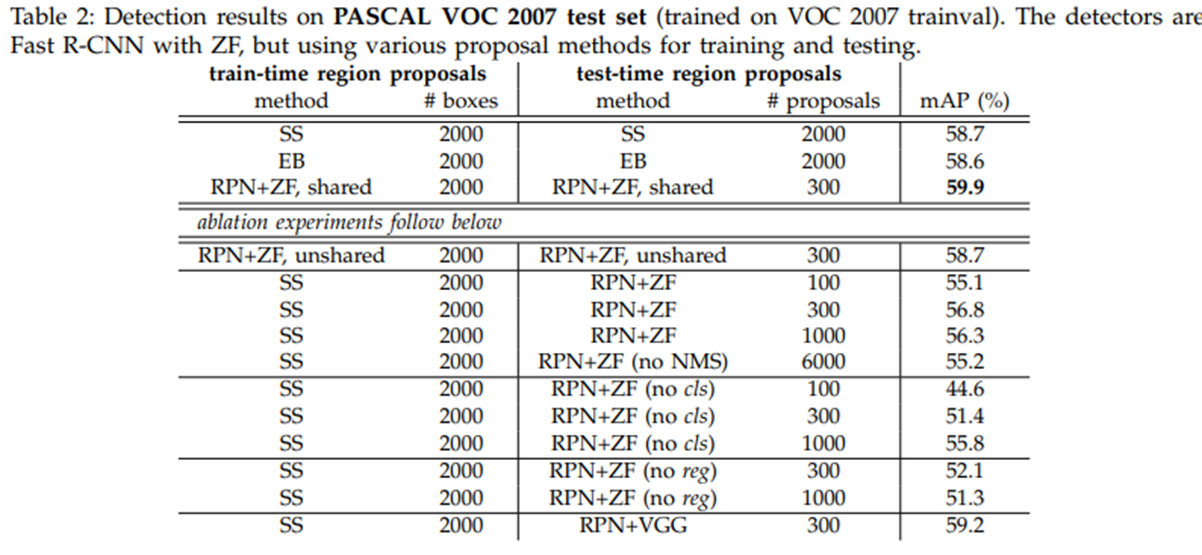
Region proposal에 여러 메서드들과 비교했을 때 RPN을 활용했을 때 가장 좋은 성능을 보이고 있습니다.

학습 데이터 셋을 변경해 가며 진행했던 실험 결과입니다.
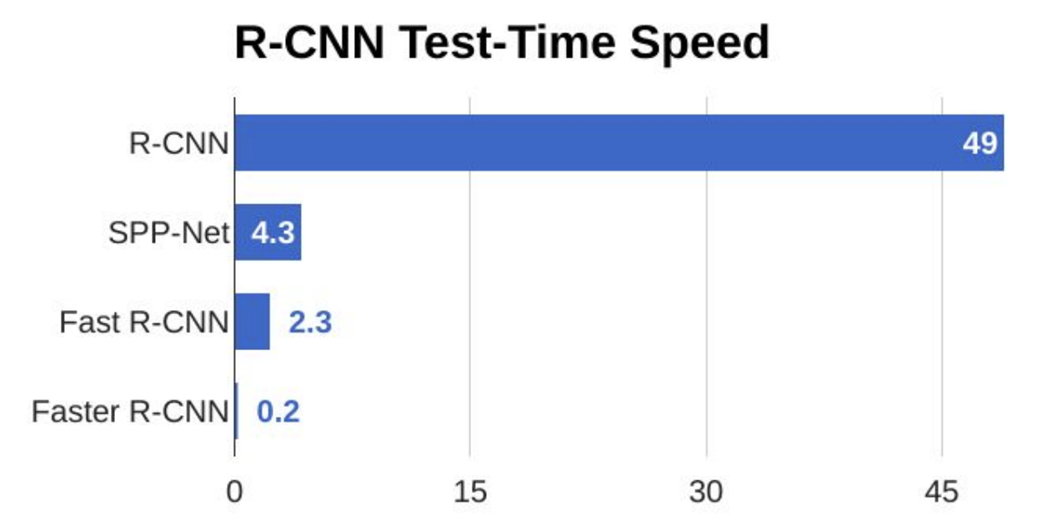
앞서 설명드렸던 네트워크 중에서도 단연 가장 좋은 속도를 보유하고 있습니다.



